Optimizing Task Scheduling and Concurrent Operations Through Redis & Postgres in Python Backend
Search for a command to run...
No comments yet. Be the first to comment.
Toast messages are a common feature in modern mobile apps, offering users quick feedback or guidance. Crafting an effective toast message involves attention to several elements, including platform-specific styles, usability, typography, color, and lo...
I set out to tackle a common issue faced by users of social media and collaborative platforms: notification fatigue. Inspired by the notification strategies employed by major platforms like LinkedIn, MS Teams, and Google Workspace, I aimed to create ...
In our previous setup, the initial problem seemed straightforward: implementing a scheduling mechanism for database queries using goroutines. This approach worked well with minimal resources and SQLite in a Go service. However, when integrating this ...
A good notification service is more than a communication channel; it can bridge the gap between the product and the users, increasing product adoption. Think of it this way: timely and relevant #alerts can nudge users with some actionable intent for ...
The problem initially appeared straightforward, but it quickly became apparent that we had underestimated its complexity. In our prior setup, we relied on goroutines to schedule database queries, enabling us to operate efficiently with minimal resources using SQLite and a Go service. However, transitioning this functionality to our SaaS platform introduced unforeseen challenges related to dynamic scheduling and concurrent task execution.
Our primary objective was to establish a systematic method for syncing data from clients' data warehouses to our data store on a scheduled basis.
Upon closer examination of our previous architecture, we identified several challenges. Users could connect their data warehouses, execute database queries, and synchronize subscribers according to predetermined schedules (e.g., hourly, daily). Initially, this setup seemed simple, especially since we utilized an embedded SQLite database and anticipated minimal concurrent executions, largely due to customers typically updating individual tables. Additionally, leveraging Golang eliminated the need for a separate scheduling process, as we efficiently managed scheduling through goroutines and the lightweight Asynq library tailored for this purpose.
Our previous setup architecture:

SuprSend's previous architecture around multi-tenancy
However, the complexity surfaced upon moving this functionality to our SAAS platform. We faced 2 challenges, dynamic scheduling from different processes and concurrent execution of those schedules, which would execute the query, process the results, and sync the subscribers.
Before going through how we arrived at the solution, let’s understand the problems more deeply.
Imagine a scenario where anyone can schedule a task at any time, and it can be set to run via a cron schedule or at fixed intervals. The scheduler should be capable of prioritizing tasks at all times and managing them efficiently. Since the schedule can change dynamically, the heartbeat process should adapt to every change.
Conceptually, this can be achieved with the help of Redis’s sorted set data structure.
Redis's Sorted Set is a powerful data structure that significantly aids in scheduling tasks by enabling efficient storage and retrieval of tasks based on their execution time or priority. The Sorted Set stores elements as unique strings (members) along with their associated scores, floating-point numbers. Internally In Redis, sorted sets are implemented using a combination of a hash table and a skip list data structure. The hash table provides fast access to elements based on their value, while the skip list maintains the sorted order of the elements based on their scores. This dual structure allows Redis to perform operations on sorted sets efficiently.
In task scheduling, scores typically represent the execution time or priority of tasks. Redis maintains the Sorted Set in ascending order based on the scores The priority of a task is determined by its score, with lower scores having higher priority. This allows for fast lookup and retrieval of tasks due for execution. If two tasks have the same scores, they are sorted lexicographically.
In the context of Redis-based schedulers, they would use Redis’s ZADD commands (to add task representation in sorted sets) and ZRANGEBYSCORE (to retrieve the highest priority task from the sorted set).
Suppose we have a task scheduling system with different priorities (low, medium, high) and execution times. We want to schedule tasks such that high-priority tasks are executed before low-priority tasks, even if a low-priority task has an earlier execution time. To achieve this, we can use a scoring algorithm that combines the priority and execution time into a single score.
Example scoring algorithm:
Copy Code
def calculate_score(priority, execution_time):
# Convert execution_time to a UNIX timestamp
unix_timestamp = execution_time.timestamp()
# Assign numeric values to priorities (lower value means higher priority)
priority_values = {'low': 3, 'medium': 2, 'high': 1}
# Calculate the score by combining the priority value and UNIX timestamp
score = unix_timestamp + (10**9 * priority_values[priority])
return score
Now, let's add tasks to the Redis Sorted Set using the ZADD command:
Copy Code
// Connect to Redis
r = redis.Redis()
# Add tasks with their calculated scores
r.zadd('scheduled_tasks', {
'Task A (low)': calculate_score('low', datetime(2023, 3, 15, 10, 0, 0)),
'Task B (medium)': calculate_score('medium', datetime(2023, 3, 15, 10, 15, 0)),
'Task C (high)': calculate_score('high', datetime(2023, 3, 15, 10, 30, 0)),
'Task D (low)': calculate_score('low', datetime(2023, 3, 15, 10, 45, 0)),
})
To retrieve tasks due for execution, we can use the ZRANGEBYSCORE command with the current UNIX timestamp as the minimum score and a large value (e.g., +inf) as the maximum score:
Copy Code
import datetime
# Get the current UNIX timestamp
current_timestamp = datetime.datetime.utcnow().timestamp()
# Retrieve tasks due for execution
due_tasks = r.zrangebyscore('scheduled_tasks', current_timestamp, '+inf')
This approach ensures that tasks with higher priority are executed before tasks with lower priority, even if they have later execution times.
Now that the scoring and scheduling part is clear let’s try to understand how we can leverage this to build a robust system that can schedule tasks from a separate producer process and utilize scheduler, worker, and Redis to function in sync.
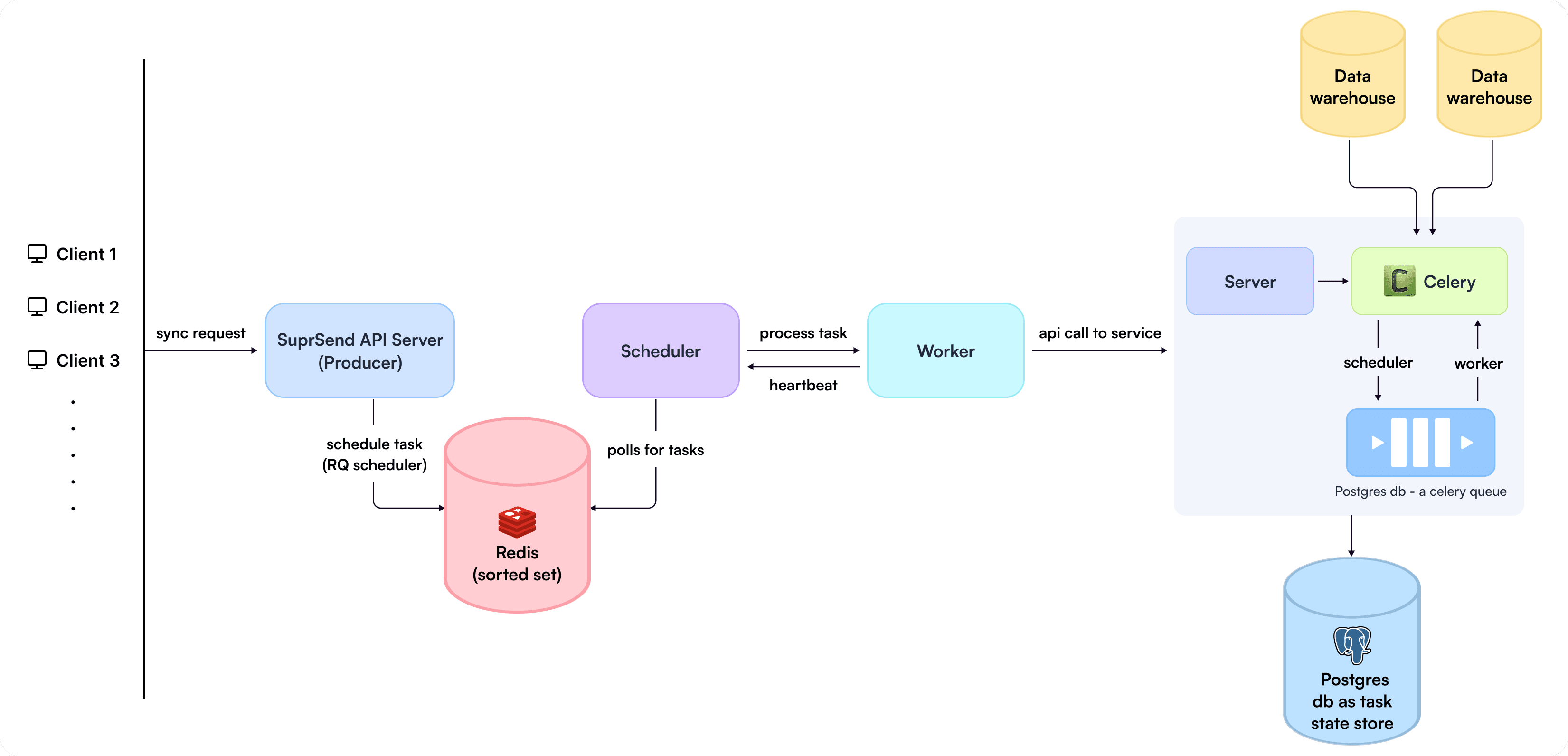
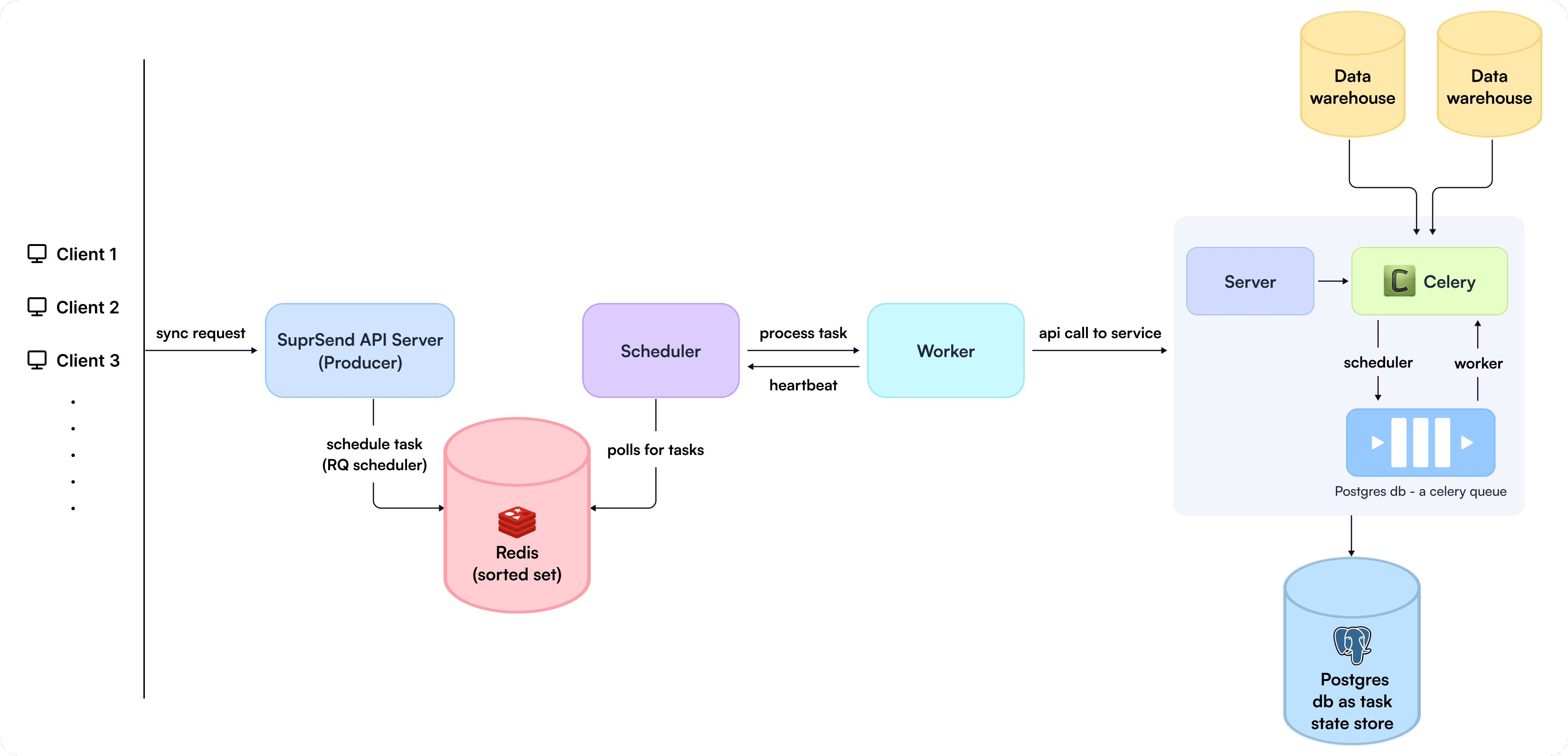
We would need a producer process/ processes to put the task in Redis using ZADD in Redis’s sorted set.
We would need a scheduler to continuously poll for tasks in Redis using ZRANGEBYSCORE and current timestamp and assign the task to existing workers.
Finally, we would need a worker process to execute the task and produce heartbeats when the task is completed so that the scheduler can update the execution progress.
In our case, the API server was our producer.
We evaluated various libraries that would utilize this unique functionality provided by Redis, and we found that rq_scheduler in Python ticks all the boxes.
We also evaluated:
APScheduler: It lacked a separate process for scheduler and worker, which is required since we would ideally want to decouple these processes from our main API server.
Celerybeat: Celerybeat didn’t support dynamic scheduling and hence wasn’t ideal.
RQ-scheduler: This implements exactly the algorithm explained above and was ideal for our use case; also, its availability in Django was a plus.
Now this is how the final architecture looked like:

SuprSend's new architecture around handling multi-tenancy
Our previous setup, SQLite, wouldn’t work for distributed applications like ours because:
Concurrency Limitations: SQLite's file-based locking can cause contention issues in scenarios with high concurrent writes.
File-based Locking: SQLite's reliance on file-level locks impedes concurrent write operations in a distributed environment.
Limited Scalability: SQLite's serverless design becomes a bottleneck as the number of nodes and concurrent writes increases.
ACID Compliance Challenges: Ensuring ACID properties across distributed nodes introduces complexities for SQLite.
Data Integrity Concerns: File-based locking can lead to data corruption or loss of integrity in distributed systems.
No Built-in Network Protocol: SQLite's direct communication with the local file system limits its use in distributed environments.
Considering the situation where we had to handle distributed writes from multiple processes on the same DB. We chose to use Redis or Postgres for our distributed application. Since each query execution involved handling multiple states and processing results in batches to alleviate server load, we opted for Postgres as our database.
Postgres solves all the abovementioned issues related to distributed and concurrent writes, and scalability support, which was ideal for our use case. The only drawback was potentially a little extra compute cost to cloud providers for Postgres usage. Still, the cost paid for a bad customer experience is much larger and potentially catastrophic.
Well, after architecting the solution efficiently, processing the queries, which can sometimes even fetch a billion rows (or more), was another critical problem to solve, which we solved by creating a separate service to process the tasks as seen in the architecture diagram, which processed the tasks and sent events to SuprSend internally for subscriber addition.
You could try this functionality directly on the platform. Signup now for free.
If you learned something from this content, consider sharing it with your dev friends or on Hackernews :)