Redis <-> RQScheduler <-> Celery for Dynamic Task Scheduling and Concurrent Execution in Django Backend
In our previous setup, the initial problem seemed straightforward: implementing a scheduling mechanism for database queries using goroutines. This approach worked well with minimal resources and SQLite in a Go service. However, when integrating this functionality into our SaaS platform, we encountered new challenges related to dynamic scheduling and concurrent task execution.
We needed to synchronize data from clients' data warehouses to our data store on a scheduled basis.

Recreating the previous setup posed two main challenges:
Dynamic Scheduling: Our original architecture allowed users to link their data warehouses, execute database queries, and synchronize subscribers on a predefined schedule (e.g., hourly, daily). Initially, this seemed manageable due to our use of an embedded SQLite database and the assumption of limited simultaneous executions. Furthermore, leveraging Golang's goroutines and the Asynq library facilitated efficient scheduling without needing a separate process. However, transitioning to our SaaS platform introduced the need for dynamic scheduling from various processes and concurrent execution of these schedules.
Concurrent Task Execution: The process involved executing queries, processing results, and syncing subscribers concurrently.
We devised a solution leveraging Redis's sorted set data structure to address these challenges. This approach would allow for efficient task scheduling and management, adapting to dynamic schedule changes.
Dynamic Scheduling:
We envisioned a scenario where tasks could be scheduled at any time, either via cron schedules or fixed intervals. Our scheduler needed to prioritize and efficiently manage tasks, adapting to dynamic changes.
We chose Redis's Sorted Set because it stores and retrieves tasks based on execution time or priority. Internally, Redis implements sorted sets using a hash table and a skip list, providing fast access and maintaining sorted order. Tasks are stored as unique strings with associated scores representing execution time or priority. Lower scores denote higher priority, enabling quick retrieval of tasks due for execution. Redis commands such as ZADD and ZRANGEBYSCORE facilitate adding tasks to the sorted set and retrieving the highest priority task, respectively.
Let’s understand with an example:
Suppose we have a task scheduling system with different priorities (low, medium, high) and execution times. We want to schedule tasks such that high-priority tasks are executed before low-priority tasks, even if a low-priority task has an earlier execution time. To achieve this, we can use a scoring algorithm that combines the priority and execution time into a single score.
Example scoring algorithm:
def calculate_score(priority, execution_time):
# Convert execution_time to a UNIX timestamp
unix_timestamp = execution_time.timestamp()
# Assign numeric values to priorities (lower value means higher priority)
priority_values = {'low': 3, 'medium': 2, 'high': 1}
# Calculate the score by combining the priority value and UNIX timestamp
score = unix_timestamp + (10**9 * priority_values[priority])
return score
Now, let's add tasks to the Redis Sorted Set using the ZADD command:
// Connect to Redis
r = redis.Redis()
# Add tasks with their calculated scores
r.zadd('scheduled_tasks', {
'Task A (low)': calculate_score('low', datetime(2023, 3, 15, 10, 0, 0)),
'Task B (medium)': calculate_score('medium', datetime(2023, 3, 15, 10, 15, 0)),
'Task C (high)': calculate_score('high', datetime(2023, 3, 15, 10, 30, 0)),
'Task D (low)': calculate_score('low', datetime(2023, 3, 15, 10, 45, 0)),
})
To retrieve tasks due for execution, we can use the ZRANGEBYSCORE command with the current UNIX timestamp as the minimum score and a large value (e.g., +inf) as the maximum score:
import datetime
# Get the current UNIX timestamp
current_timestamp = datetime.datetime.utcnow().timestamp()
# Retrieve tasks due for execution
due_tasks = r.zrangebyscore('scheduled_tasks', current_timestamp, '+inf')
This approach ensures that tasks with higher priority are executed before tasks with lower priority, even if they have later execution times.
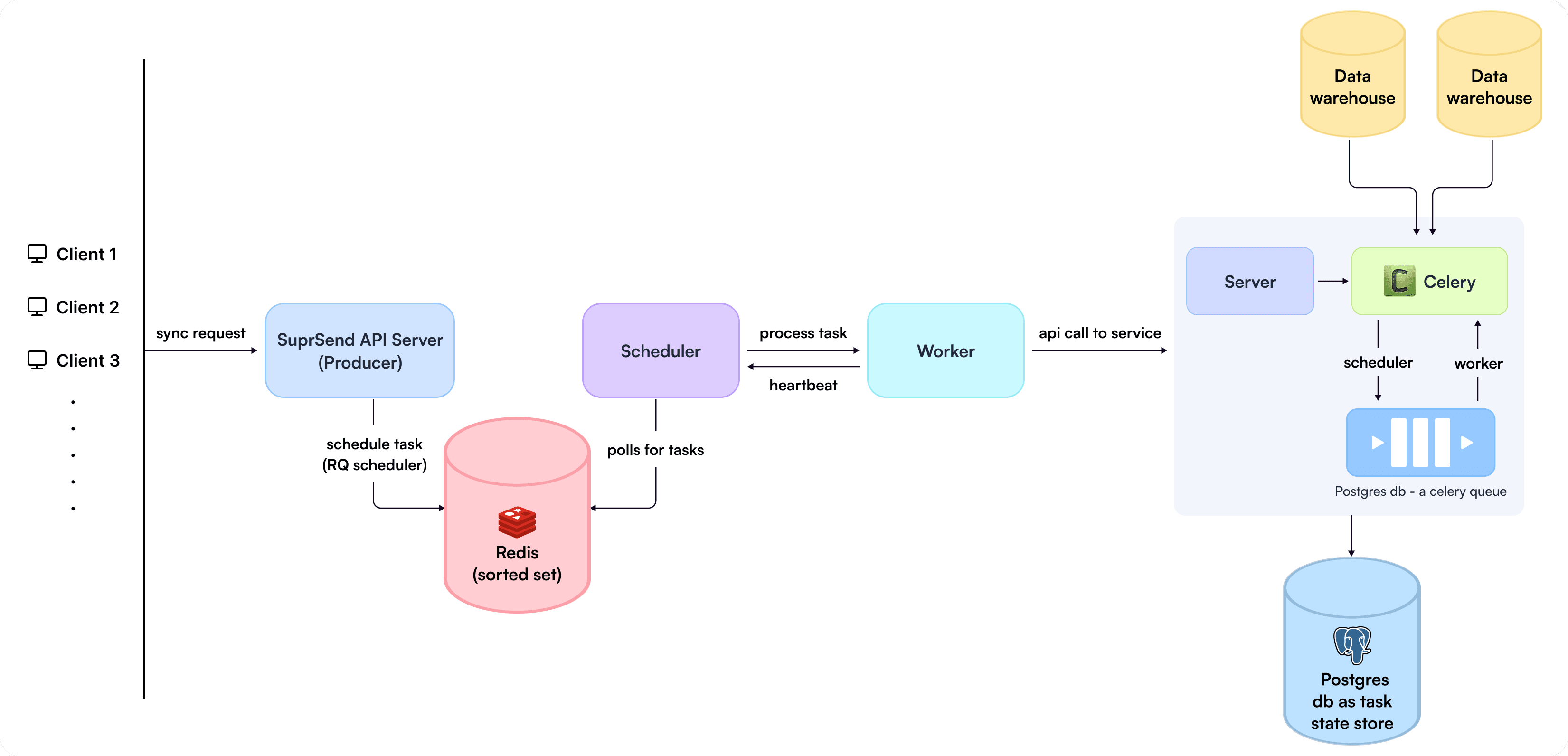
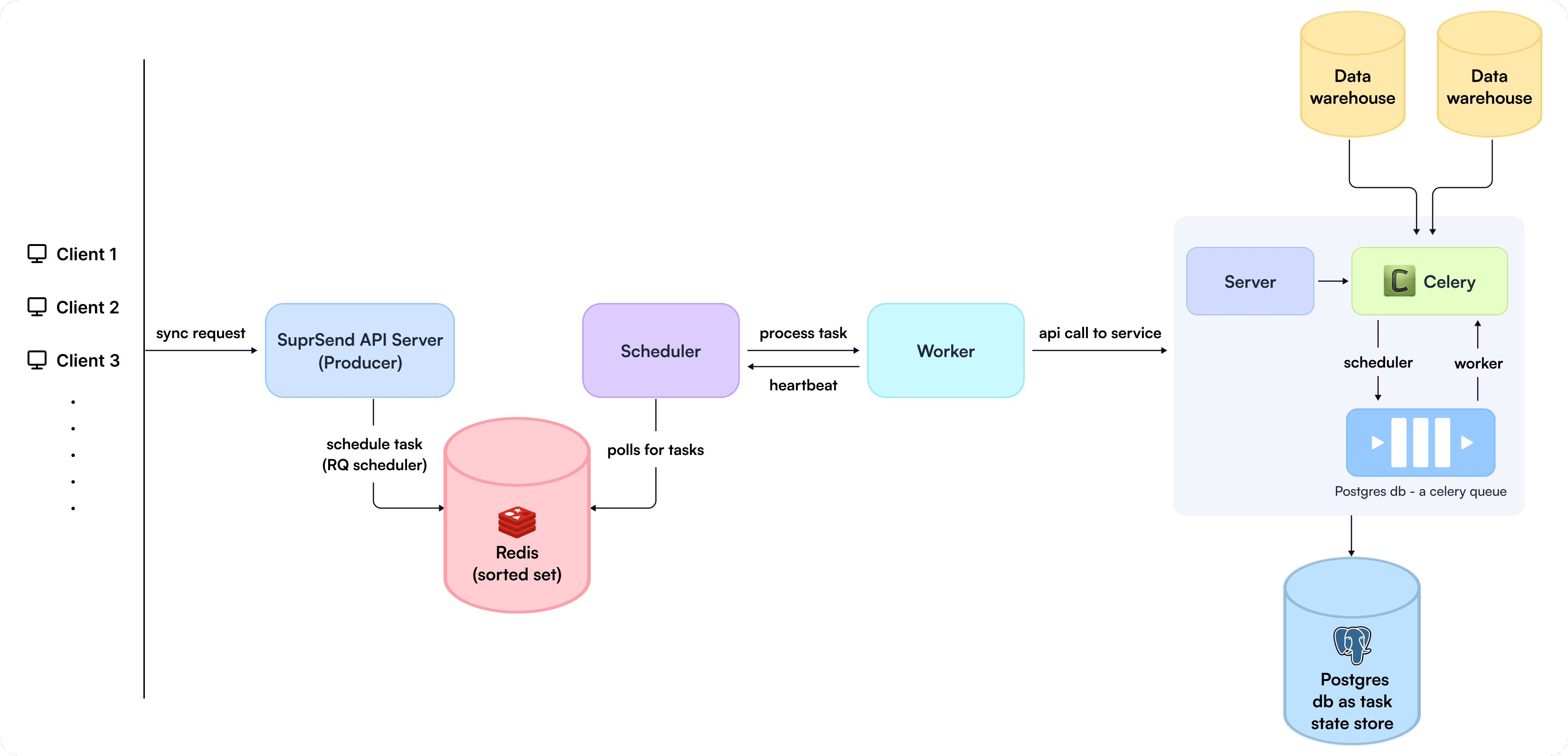
Now that the scoring and scheduling part is clear let’s try to understand how we can leverage this to build a robust system that can schedule tasks from a separate producer process and utilize scheduler, worker, and Redis to function in sync.
We would need a producer process/ processes to put the task in Redis using ZADD in Redis’s sorted set.
We would need a scheduler to continuously poll for tasks in Redis using ZRANGEBYSCORE and current timestamp and assign the task to existing workers.
Finally, we would need a worker process to execute the task and produce heartbeats when the task is completed so that the scheduler can update the execution progress.
In our case, the API server was our producer.
Implementation:
We evaluated various libraries that would utilize this unique functionality provided by Redis, and we found that rq_scheduler in Python ticks all the boxes.
We also evaluated:
APScheduler: It lacked a separate process for scheduler and worker, which is required since we would ideally want to decouple these processes from our main API server.
Celerybeat: Celerybeat didn’t support dynamic scheduling and hence wasn’t ideal.
RQ-scheduler: This implements exactly the algorithm explained above and was ideal for our use case; also, its availability in Django was a plus.
Now, this is how the final architecture looked like:

SuprSend's new architecture around handling multi-tenancy
For Concurrent DB Writes
Our previous setup, SQLite, wouldn’t work for distributed applications like ours because:
Concurrency Limitations: SQLite's file-based locking can cause contention issues in scenarios with high concurrent writes.
File-based Locking: SQLite's reliance on file-level locks impedes concurrent write operations in a distributed environment.
Limited Scalability: SQLite's serverless design becomes a bottleneck as the number of nodes and concurrent writes increases.
ACID Compliance Challenges: Ensuring ACID properties across distributed nodes introduces complexities for SQLite.
Data Integrity Concerns: File-based locking can lead to data corruption or loss of integrity in distributed systems.
No Built-in Network Protocol: SQLite's direct communication with the local file system limits its use in distributed environments.
Considering the situation where we had to handle distributed writes from multiple processes on the same DB. We chose to use Redis or Postgres for our distributed application. Since each query execution involved handling multiple states and processing results in batches to alleviate server load, we opted for Postgres as our database.
Postgres solves all the abovementioned issues related to distributed and concurrent writes and scalability support, which was ideal for our use case. The only drawback was potentially a little extra compute cost to cloud providers for Postgres usage. Still, the cost paid for a bad customer experience is much larger and potentially catastrophic.
Well, after architecting the solution efficiently, processing the queries, which can sometimes even fetch a billion rows (or more), was another critical problem to solve, which we solved by creating a separate service to process the tasks as seen in the architecture diagram. Which processed the tasks and sent events to SuprSend internally for subscriber addition.
Anyways, this is how SuprSend notification infrastructure architecture works to abstract the pain of building and maintaining notification service on your end. What do you think?

Why We Use Both RQ and Celery?
RQ to schedule the task and celery to handle task execution; since tasks can be long/heavy, we didn't want rq workers to get blocked or in error cases, handle restarts. And as you rightly said, we didn't want to spend extra efforts managing and actively maintaining the RQ backend in the future, whereas we already actively manage and maintain celery. Hence, Celery would be better suited to handle task execution and free up extra bandwidth and load for RQ workers.
Also, it's better to stick with the native workers and scheduler provided by the task queue system you're using (either Celery or RQ). This ensures compatibility, simplicity, and optimal resource utilization. Also, we'd want RQ workers to handle smaller tasks in the future, whereas coupling Celery workers with RQ schedulers introduces an extra layer of complexity, i.e., configuring celery workers to also listen to RQ's task queue, and handling failures, errors, retries, which just makes it even more complex.
You could try this functionality directly on the platform. Signup now for free.
If you learnt something from this content, consider sharing it with your dev friends or on Hackernews :)